Research Statement
The wealth of existing data, often referenced both in space and time, enable novel classes of applications and services of high societal and economic impact. Modern applications, including social networks, scientific databases, bioinformatics, open governmental data, produce vast volumes of data that are often publicly available, although quite diverse, unrelated and raw.
This poses important challenges for next-generation data management systems, targeting to turning data into knowledge, aiming to affect many important sectors of human life.
Our goal is to address the challenging problems related to the wealth data, by advancing research and producing solutions to real world problems related to efficient and scalable management of Big Data (gathering and cleansing data, storing and indexing data, analyzing, and mining data). Our view of processing big data includes both, batch-style analytical processing and real-time processing.
Emerging issues, such as semantic- and privacy-aware querying and mining, as well as distributed processing of data and integration of data sources through scalable solutions for semantic enrichment and alignment, are in focus.
Highlights

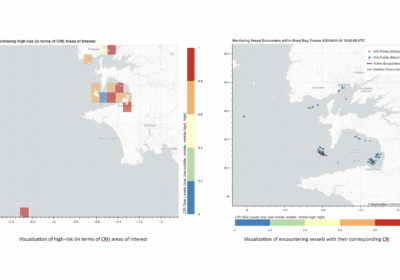
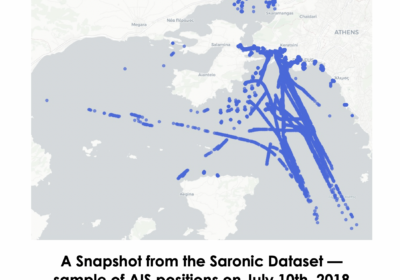
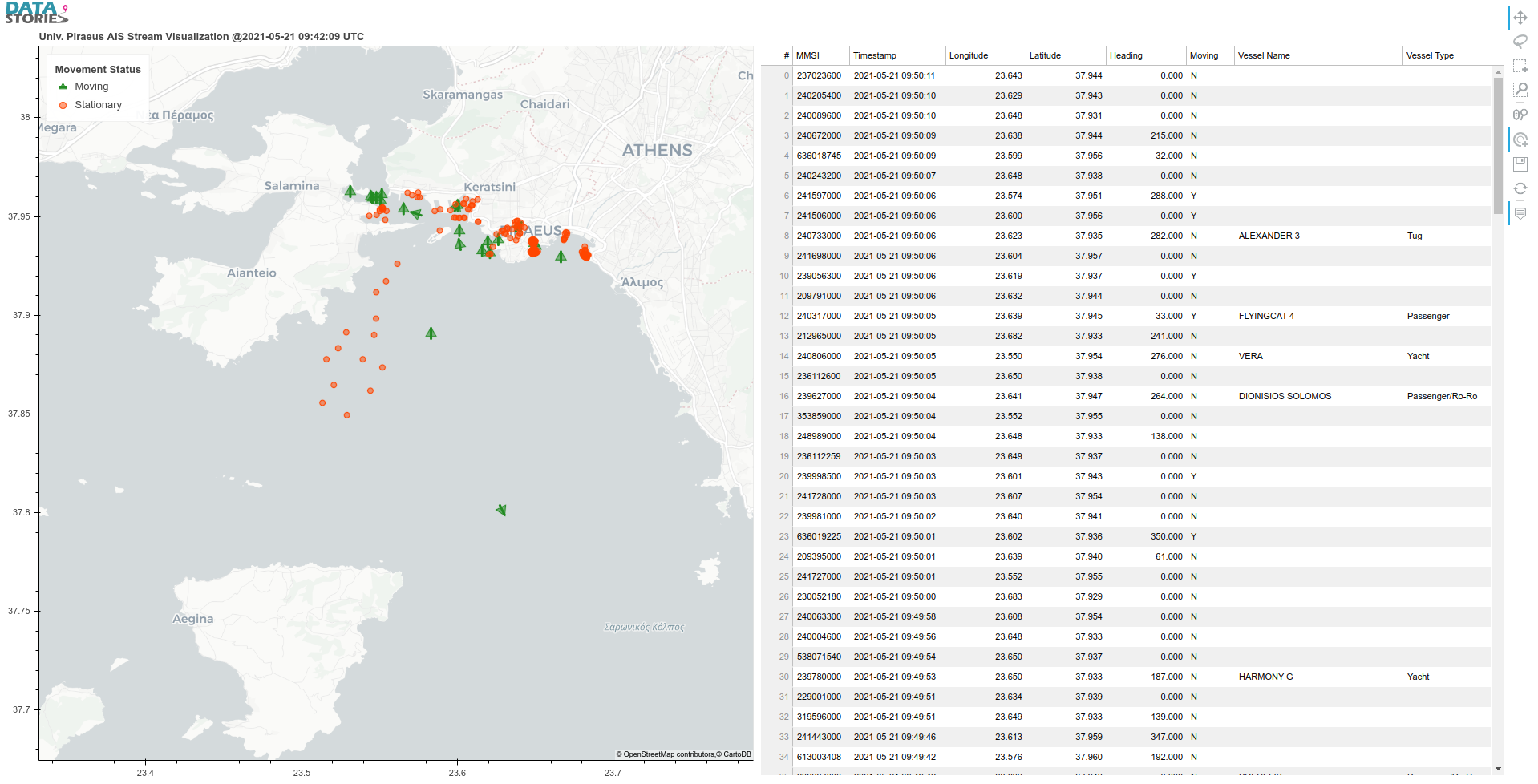
VesselVision: Fleet Safety Awareness over…