Data Science Lab
University of Piraeus
|
Data Science Lab University of Piraeus |
Abstract
S2T-Clustering
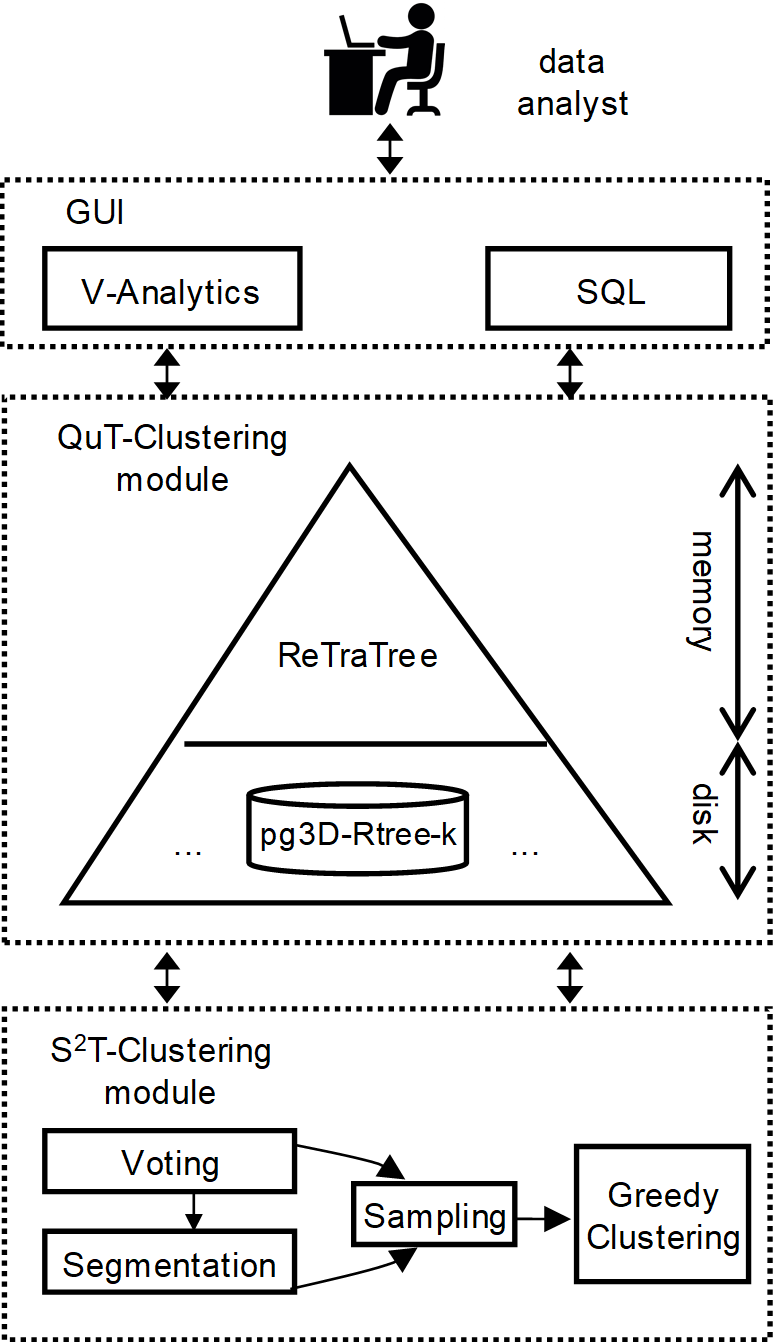
In more detail, during the adopted voting process each 3D trajectory segment of a given trajectory is voted by other trajectories w.r.t. their mutual distance. The voting received by each segment is a value ranging from 0 to N (N being the cardinality of the MOD) that has the physical meaning of how many trajectories co-move with that trajectory for a certain period of time. After the voting process takes place, the trajectory segmentation process follows. The goal of this step is to partition each trajectory into sub-trajectories having homogenous representativeness, irrespectively of their shape complexity. However, the goal of sub-trajectory clustering is to partition the entire dataset into groups (clusters) and to detect the outliers among the sub-trajectories identified by the trajectory segmentation step. Therefore, in our proposal, we first select the appropriate sampling set S and then, we tackle the problem of clustering according to the following idea: each sub-trajectory in the sampling set is considered to be a cluster representative. So, the sampling set should contain highly voted trajectories of the MOD which, at the same time, would cover the 3D space occupied by the entire dataset as much as possible. Then, the clustering is done building the clusters around those representatives. For more details about S2T-Clustering, please refer to [1].
QuT-Clustering
Given a MOD indexed according to ReTraTree structure and a temporal period W of interest, QuT-Clustering efficiently retrieves the subset of the MOD, actually the clusters and outliers at sub-trajectory level, that temporally intersect W.
System Architecture
Having this functionality in hand, the data analyst is able to perform interactive clustering analysis, by providing different values of W as input, through either the SQL interface of Hermes@PostgreSQL [3] or the incorporated V-Analytics tool [4].
References